
Explanation and proof
Programming languages do not exist only to communicate instructions to the machine. They exist to turn vague ideas into formal representations, free of ambiguities.
The impact of generative AI tools based on LLMs on the software development industry has been undeniably considerable (and controversial). Among the various questions and reflections that have been raised, one in particular catches my attention: what will become of programming languages now that agents are capable of writing entire programs through cycles of interaction with humans? Given that these interactions are based on the explanation of program specifications in natural language, would the formulation of a program representation in JavaScript, C, Rust or Go, for example, become obsolete, redundant. If so, why should we teach new generations to program? The agent could generate the binary code, ready to be executed, right? Well… maybe not exactly. The mistake I see in this outlook lies in not observing the fundamental difference between explanation and proof.
A good prompt
A person can explain to the machine commands, behaviors, and characteristics that they would like to integrate into a program. Natural language, however, intrinsically carries ambiguities, which have their function in human communication, but which condition the understanding of the explanation to a non-deterministic character. That is, it is possible that the interpretation of the message by the receiver finds compatibility with the sender’s intention, but it may also not.
Source code, on the other hand, makes use of formal structures to define flows and logical relations, scope, variables, etc.. This guarantees deterministic correspondence between what is represented in the code and the effect of its execution. Therefore, a program, when proving the idea in its code, does not simply communicate its characteristics, but is incorporated by the machine that executes it when it guarantees a deterministic execution.
It is often said that a good prompt should use the right words, should be constructed in a succinct and objective manner, exposing specific points of interest, cannot contain superfluous information, etc.. All this care serves so that the machine does not get lost in interpretations that deviate from the original intention of the prompt. If we kept narrowing the possibilities of communication (words that can be used, syntactic formulations) to mitigate ambiguities, what would be the result? Would this not be the conversion of a natural language into a formal language?
A mathematical point of view
In the software development process, we start from the collection of requirements that consolidate an idea, still at a high level of abstraction. When we use a programming language to transcribe such an idea into source code, we are defining a representation that seeks to formalize it.
To illustrate this point, let us turn to mathematics. Consider the following description:
A line starts from the ground, passes through the point where the height is 1 meter above the ground, and touches the ground again one meter from the origin.
Now let us try to represent this idea through a drawing.
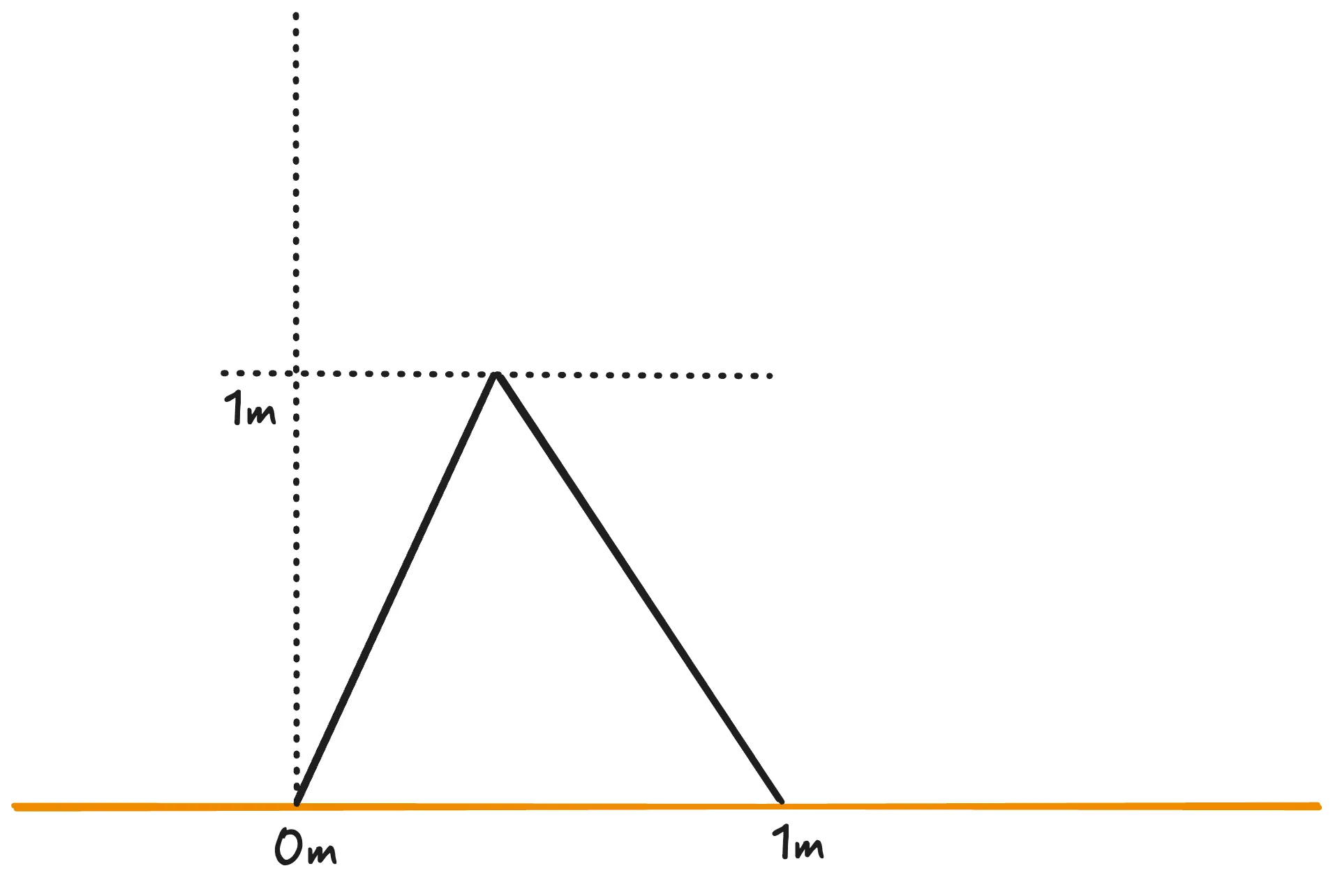
All the requirements of this first explanation are verifiable in the graphic representation above, however, it is not necessarily accurate in relation to the idea initially imagined. We can reiterate the explanation and try to get closer to the idea, but it will always carry a degree of imprecision that turns this search into something practically random.
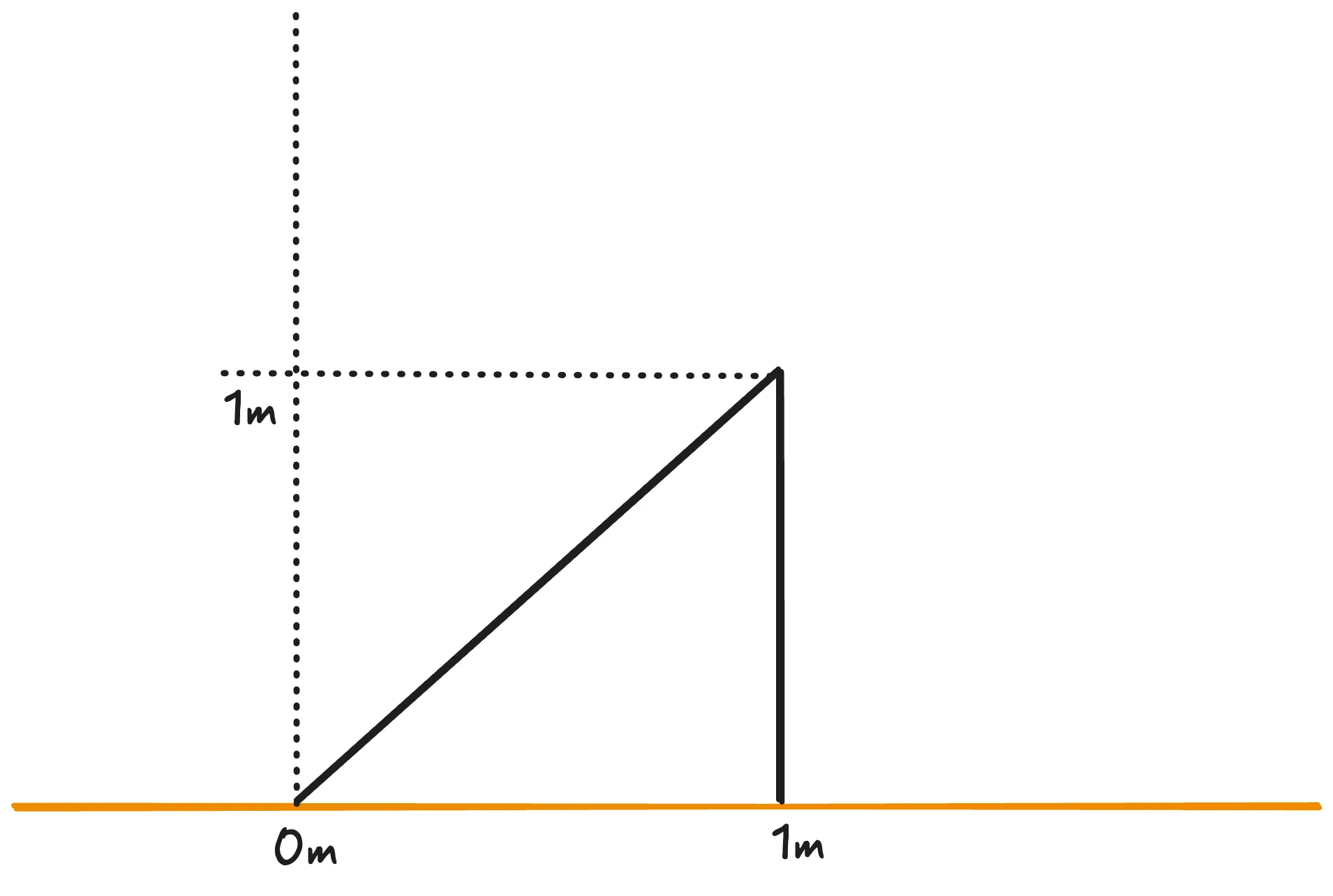
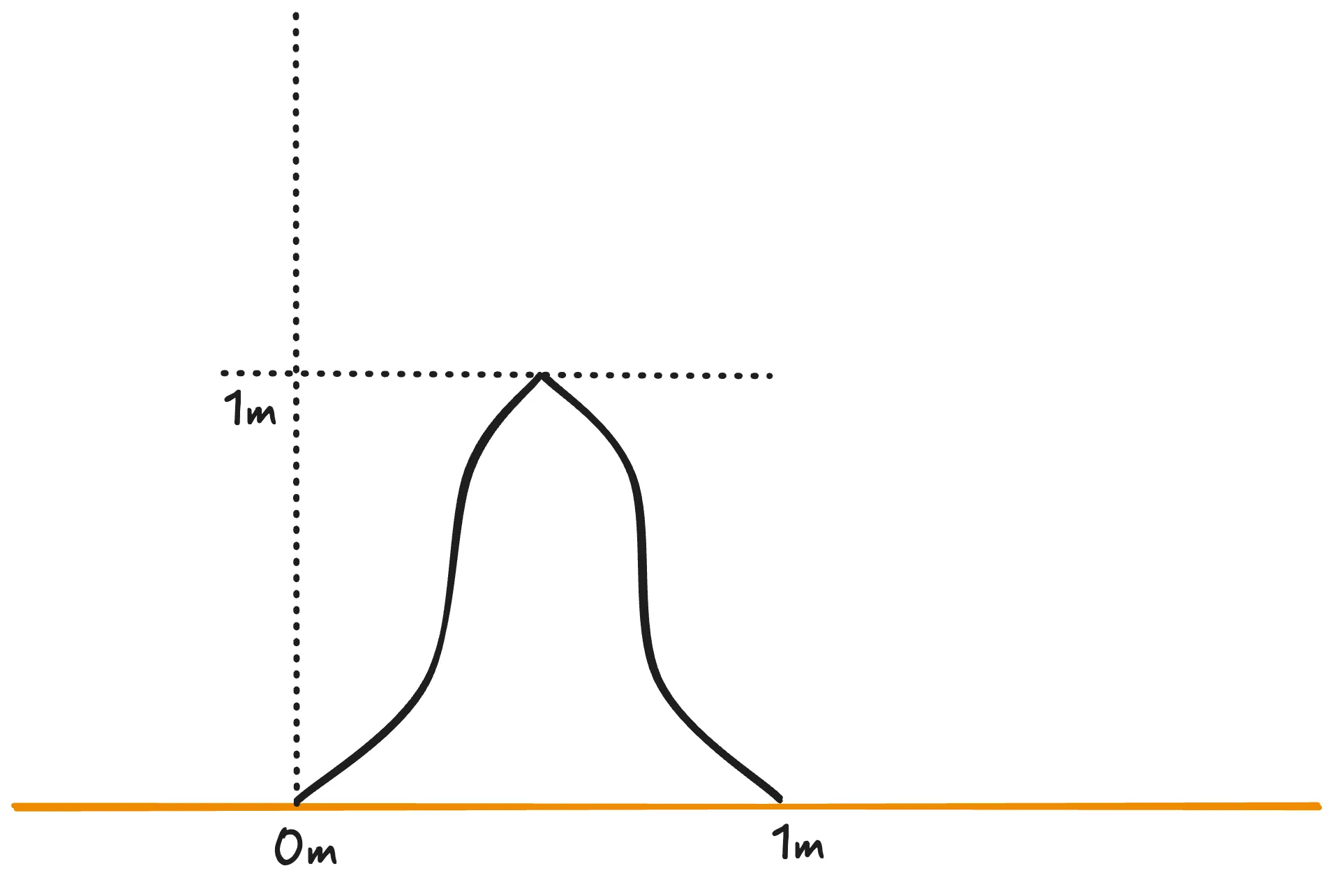
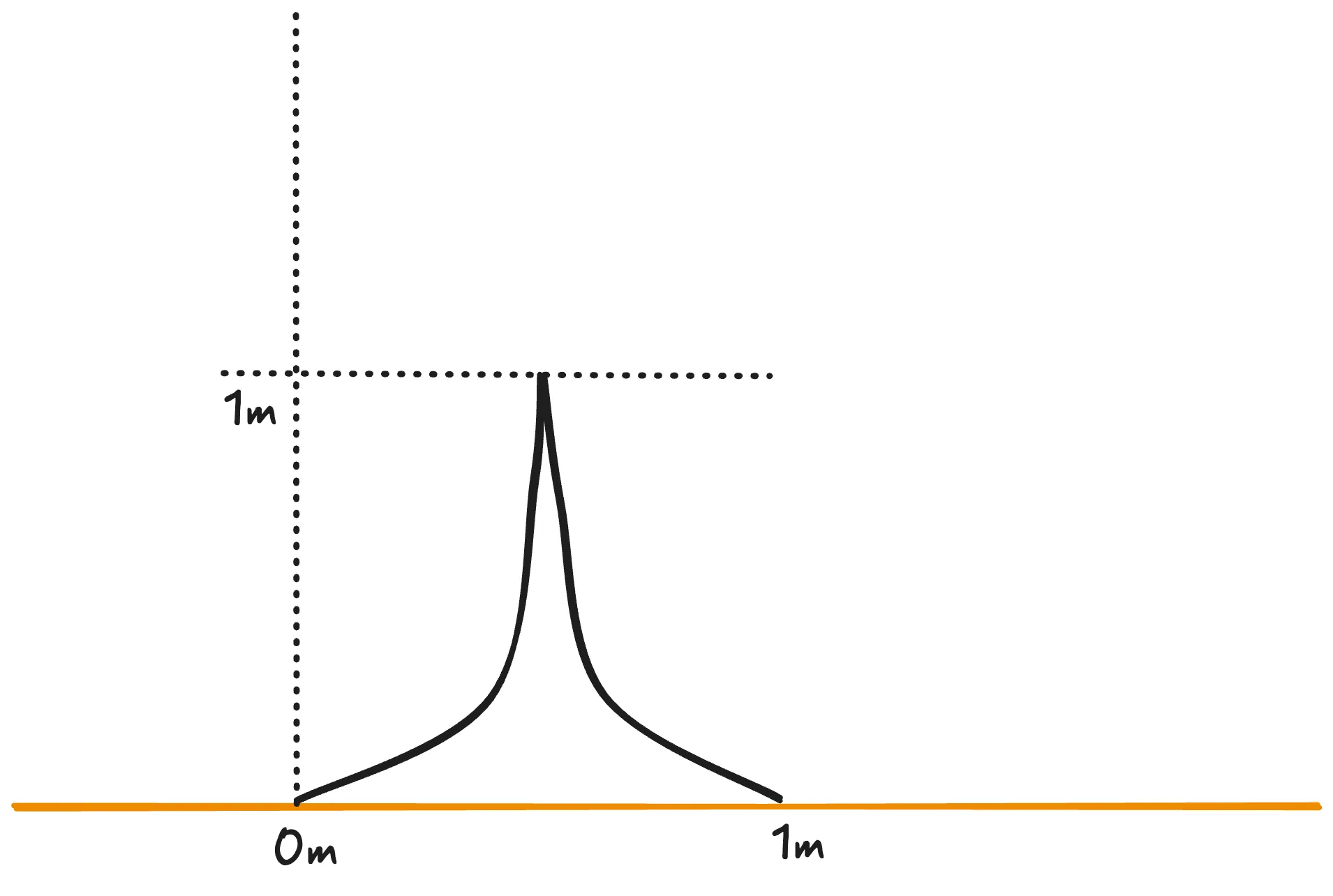
Finally, let us describe the line using the following notation:
x -> distance in meters with origin at the starting point of the line,
y -> height in meters starting from the ground
Thus, it is possible to observe the unambiguous position of the line at each point of the trajectory between the origin and the destination.
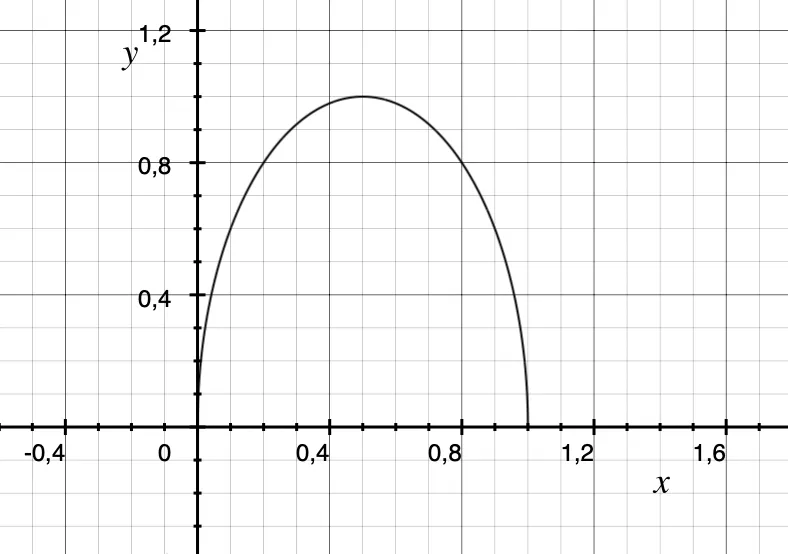
This precision and observability is only achieved through the proposal of a formal proof of the idea, which excludes ambiguities. If we say that the line still does not correspond to the initial specification (which would be a bug), we can and know how to adjust the given mathematical expression in order to reach the desired result. Mathematical expressions and computational programs, equivalent by their formal nature, share this same capacity.
Who will read tomorrow’s code?
What LLM-based AI agents currently do is translate an explanation, given in natural language, into source code made with scraps. To completely remove the human burden of learning the syntax rules of a formal language, delegating all the weight of interpretation to the machine and its language models may seem tempting. However, I do not believe it is desirable for anyone (companies, banks, hospitals, government agencies, etc..) for programs to become unobservable artifacts, virtually unfixable, whose only possibility of rectification would be yet another prompt and faith that the agent gets the specification right. There will always be a need for someone to validate, maintain, interpret failures, and certify the safety of what is produced. We are bound to the need to keep programs in a form that is intelligible to us and incorporable by the machine. Programming languages continue to be fundamental elements in software engineering and, with that, the need for people who understand them.